포스팅 목적
왜 이렇게 코드분석이 안될까, 코드작성이 안될까 생각했는데
내가 groupby함수를 제대로 이해하고 사용하지 못하는 데 원인이 있는 것 같았다.
특히 cumcount() 사용에 있어서 헷갈렸는데, 이부분 좀 더 익숙하게 체화시키기 위해 정리해보자.
groupby 공부하기
첫번째, 그룹바이 객체
특정 칼럼으로 그룹바이를 호출하면, 그룹바이 객체를 반환한다는 사실.
이 사실을 인지하고 있는것과 모르는것은 큰 차이가 있다.
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'],
'Max Speed': [380, 370, 24, 26]})
print(df, '\n')
gb_animal = df.groupby('Animal')
print(gb_animal)

두번째, 그룹바이객체에 통계함수 사용
반환된 그룹바이객체에 통계함수를 사용하면, 멋진 데이터프레임을 반환합니다!
count()함수를 사용하면 각 Animal의 수를 반환하고,
sum()은 합을 반환, nunique()는 고유값 개수를 반환합니다.

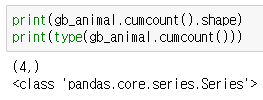
cumcount()는 count()와 비슷한데 각 데이터 건마다 중복 번호를 계산합니다!
예외적으로 데이터프레임을 반환하는 것이 아니라 시리즈를 반환합니다.
animal groupby에서는 4개의 데이터건이 있으므로 (4,) 의 시리즈가 나옵니다.
이 외에도 그룹바이에 사용할 수 있는 대표적인 통계함수들은 아래와 같습니다!
| count, sum | 개수, 합계 |
| mean, median | 평균, 중앙값 |
| var, std | 분산, 표준편차 |
| min, max | 최소, 최대값 |
| nunique | 고유값 개수 |
| prod | 곱하기 |
| cumcount | cumulative count |
맺으며
간단한 사용법만 알아봤다.
다음에 그룹바이를 더 잘 써야하는 상황이 생기면, 두번째 포스팅을 이어나가야겠다.
'CS > Python' 카테고리의 다른 글
| [코드 스터디] UCI-HAR 데이터셋1: 중복칼럼 확인 (0) | 2022.10.28 |
|---|---|
| pandas.DataFrame.apply 함수 기본 사용법 (0) | 2022.10.27 |
| Pandas merge함수 사용법 기초 (0) | 2022.10.26 |
| numpy.r_ 연산자 사용법 (0) | 2022.10.21 |
| 피쳐 중요도 feature_importances_ (0) | 2022.10.18 |

댓글